


Adresse
1 rue de Saint-Petersbourg75008 Paris
Mail
contact@bam.techTéléphone
+33 (0)1 53 24 00 83Last week I had to make a dashboard to display KPI about a big business. I was impressed about all the data they have saved! They have real-time data from an API, and mid and long term data in Big Query. The dashboard was pretty simple to develop, but the strategy to get the right data at the right time without consuming too much data was so complex I decide to make a Proof Of Concept about the best strategy to adopt. I chose to develop my dashboard with NextJS to take advantages of Server Side Rendering (SSR) in a React application.
You will find all the examples detailed in this article on this Github repository
The cache for a front-end application is the mechanism that store your fetched data temporarily to avoid your application to fetch the data on the server whereas it has not changed from the last time. It avoids lots of API call either bandwidth consumption. Moreover, if your application has lots of users, and you administrate yourself your server, you know without doubt that you have to dimension your server to absorb all the traffic for your pic of charge. If each of your user call your server to get a resource which does not change with the time, then your server has to be able to accept a big charge of use, instead of using a cache which allow you to pay for a smaller server without comprising your application reactivity?
For my use case, the data stored in Big Query are analytics about the day-to-day sales. So they are updated each day, and each past day data does not change in time. Moreover, I have a lot of amounts of data to deal with. Whereas Big Query is very efficient to do requests in very big database, it could take between 1s to 5s for the biggest requests, and this is not acceptable for a dashboard application. The magnitude of a classic API is a few hundred of milliseconds. With our mean of 2s per request, our application would be very slow. If you add to this fact that in a dashboard you're not 1, not 2, but about ten KPI a screen, you can imagine how long could be the first render of a page.
A strategy to adopt is to save each request result temporarily to be able to access it without calling the Big Query API. In this way, we would be able to access our data to display quickly, without consuming our Big Query credits.
In fact, there is no only one way to use the cache to improve our application performance. You can use :
The first thing to know is that your browser handle automatically your cache for you in some case! For my API calls, I use ++code>fetch++/code> because it is the most common way to do this. And what is great is that ++code>fetch++/code> manage the client-side cache very well.
Let's try it!
For the demonstration I will use the NextJS framework which is a React framework to make server-side rendering application (but single page app too!). I chose NextJS to improve dashboard screen rendering. Indeed, the NextJS application can download the KPI server-side, and is not constrained by the client bad network. Moreover, it provides API routing to avoid deploying a server in addition.
Setup your NextJS application:
++pre>++code>++code>yarn create next-app --typescript++/code>++/code>++/pre>
You should be able to launch your application by running ++code>yarn dev++/code>, then going to your browser and connecting to the "localhost:3000" URL.
I chose to set up a server outside our NextJS application, and not using the NextJS API routing to prove you that the cache is dissociated from NextJS, but is inherent to the browser client side, or the server.
Look at the Express documentation to setup your Express server
Note : change the default Express port to another port, because the NextJS application is already using this port. I used the 8080 port for instance.
Create a ++code>nocache++/code> route on the server (after the "/" default hello world route).
++pre>++code>++code>app.use((req, res, next) => {
setTimeout(() => { // simulate a long api call of 1 second
next();
}, 1000);
});
app.get("/nocache", (req, res) => {
console.log(Date.now(), "Delivering some no-cached content");
console.log("Host : ", req.headers.host, " - Origin : ", req.headers.origin);
res.status(200).json(mockPosts); // mockPosts is a JSON with mock data get from https://jsonplaceholder.typicode.com/posts
});++/code>++/code>++/pre>
Mock your API data by copy/paste the result of the following request : https://jsonplaceholder.typicode.com/posts. It is my mockPosts.
To simulate a long API call, I introduced a middleware with a ++code>setTimeout++/code> which wait for 1 second before returning a response to my client application.
Then I write my client page to call my API and display the results. I designed a Card component to improve ode readability
++pre>++code>++code>// pages/nocache.tsx
import type { NextPage } from "next";
import { useEffect, useState } from "react";
import { ROOT_URL } from "../src/constants";
import { Post } from "../src/types/api/post";
import { Card } from "../src/atoms/Card";
const NoCache: NextPage = () => {
const [data, setData] = useState<Post[] | null>(null);
useEffect(() => {
(async () => {
try {
const res = await fetch(`${ROOT_URL}/nocache`); // ROOT_URL = "http://localhost:8080" because my server is linstening on the 8080 port
const response = await res.json();
setData(response);
} catch (e) {
console.warn(e);
}
})();
}, []);
return (
<div
style={{ display: "flex", flex: 1, flexDirection: "column", padding: 24 }}
>
{!!data && data.map((item) =><Card key={item.id} title={item.title} />)}
</div>
);
};
export default NoCache;++/code>++/code>++/pre>
Now launch your server in a terminal, your NextJS application in another terminal, and go to your client application in your browser (http://localhost:3000).
You should see your post list
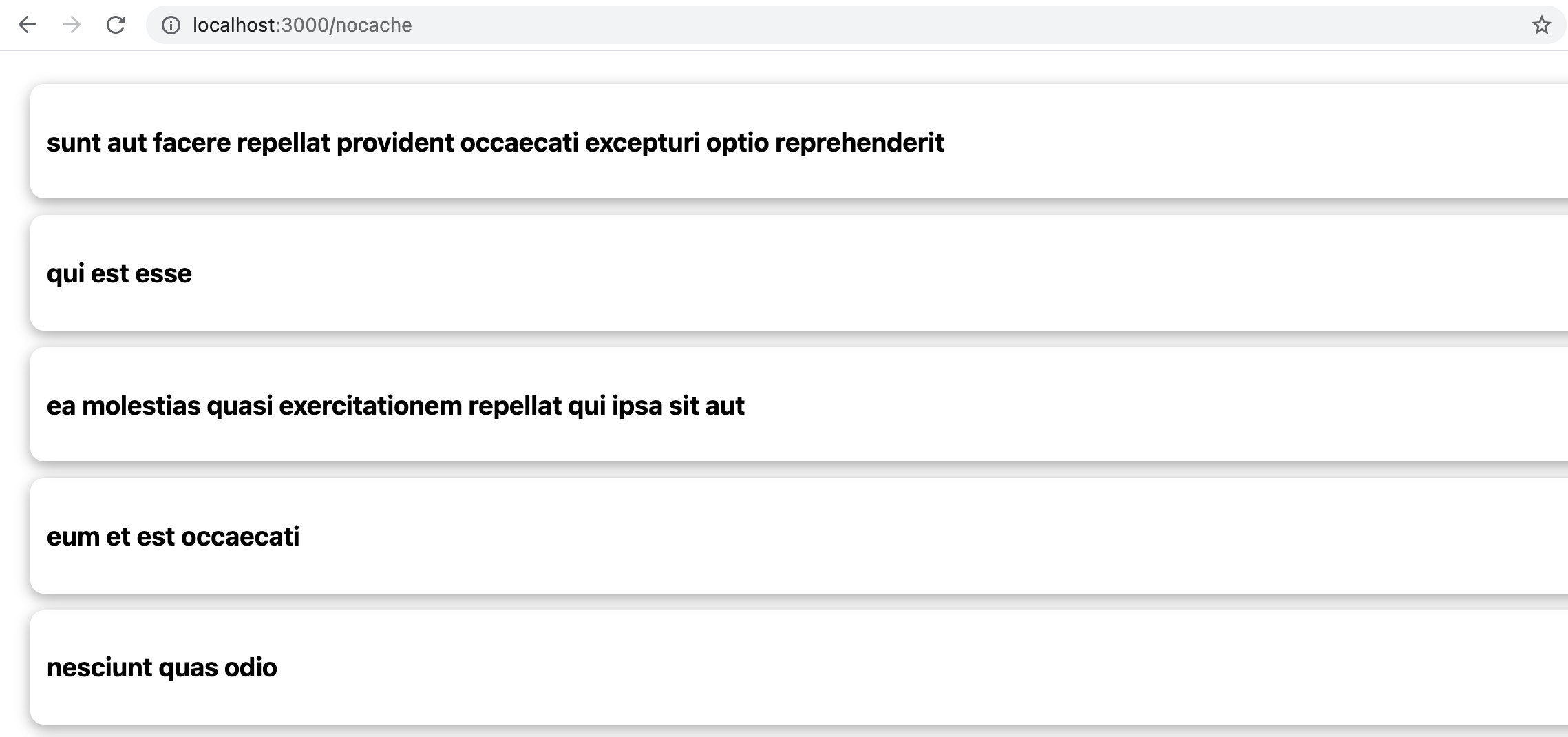
Now if you open your developer tools (F12 for Chrome), and go to the Network tab, you can see your ++code>/nocache++/code> API call if you refresh your page
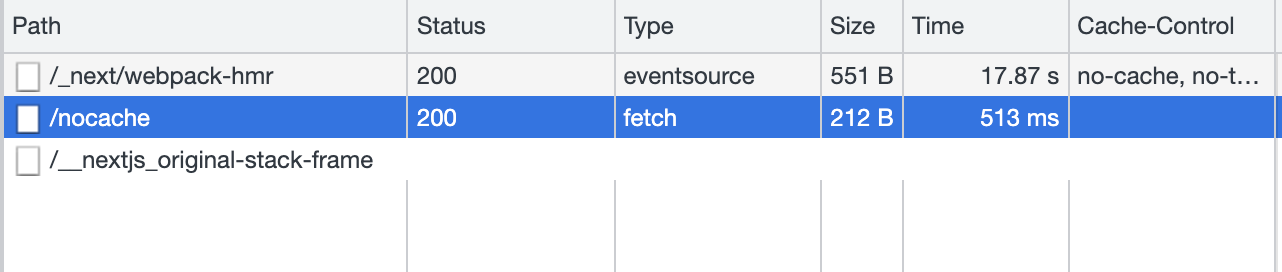
The dev tool shows that the data fetched took 513ms to download, and has a size of 212 bytes (yes it is not so much, but it is mocked data ?)
Note: if you don't see the same column as me, a right click on the header should allow you to display information you want.
Now if you refresh your page, the API call is done again, the time is almost the same (512ms for me). Indeed, if you hover the 212B data, a tooltip displays that the data is transferred over the network (and not from the cache)

I told you that ++code>fetch++/code> as a built-in cache. Yes, it is true, but you have to tell to ++code>fetch++/code> that your data you send can be cached. Indeed, by default, ++code>fetch++/code> does not cache your data. It is rather good, because it avoids to display stale data to your user! What if you displayed the score of a football game with a cache? If your favorite team goals, then your website will still display the old score ?
Create a new server route with a Cache-control header:
++pre>++code>++code>app.get("/cache", (req, res) => {
console.log(Date.now(), "Delivering some cached content");
res.set("Cache-control", "public, max-age=30");
res.status(200).json(mockPosts);
});++/code>++/code>++/pre>
By adding a ++code>Cache-control++/code> header with a ++code>max-age++/code> of 30, we are telling to the client that the data sent is valid for 30 seconds, after this delay, the data is staled and the browser has to fetch again the API.
No modification is needed. Indeed, as I told you, ++code>fetch++/code> handles the cache for you ?
Just one point : refreshing the page remove the cache because it is an in-memory cache, so for each refresh the cache is deleted. But when navigating into NextJS app with the Link component, the app is not refreshed, just page components are rendered at the right time to display the right page. So what you need to do is to add ++code>Link++/code> from next/link on the home page to redirect to the ++code>/cache++/code> page, and a`Link` to the home page (++code>/++/code>) on the cache page. For the content of the ++code>/cache++/code> page you can copy/past the ++code>/nocache++/code> page, it is the same except the API route called which is no more ++code>${ROOT_URL}/nocache++/code> but ++code>${ROOT_URL}/cache++/code>.
Go to the home page, open the dev tools (F12), then go to the ++code>/cache++/code> page with the new link. You should see the same API call to ++code>/cache++/code> route the first time

Then, if you go back to home with the Link button, and come back to the ++code>/cache++/code> page, you should see that the ++code>/cache++/code> API call took 1ms! ?

500 times less? Wohaou! It is awesome, yes it is! It is called cache ? Indeed in the size column you can see that the data is read from "disk cache" instead of "transferred from network". You have the proof that in-memory cache is very fast. Now if you watch your server terminal, you should not see a log for the second page refresh, indeed your API is not called at all!
This demonstration is impressive, but what if you want to control your cache client side without having access to the server response header?
Libraries like React Query handles this difficult thing for us!
React Query is a data-fetching library for React Query. It is not the only one (I think about swr too), but it is a good one we use at BAM.tech. With react-query dev tools we are able to see the cache state (fresh, stale, fetching, inactive) to see easier what is happening under the hood. The react-query cache is a layer added in addition to the http client (like ++code>fetch++/code>) cache. It allows the library to manage its own cache like it wants.
First you have to install react-query, then add the provider to be able to use it inside your app. You can add this provider in the _app.tsx file. Optionally, you can add the dev tools to your app. Finally, setup react-query SSR with NextJS using hydration.
Now you should have this entry file:
++pre>++code>++code>// _app.tsx
import "../styles/globals.css";
import type { AppProps } from "next/app";
import { QueryClient, QueryClientProvider } from "react-query";
import { ReactQueryDevtools } from "react-query/devtools";
import { Hydrate } from "react-query/hydration";
import { useState } from "react";
function MyApp({ Component, pageProps }: AppProps) {
const [queryClient] = useState(() => new QueryClient());
return (
<QueryClientProvider client={queryClient}>
<Hydrate state={pageProps.dehydratedState}>
<Component {...pageProps} />
</Hydrate>
<ReactQueryDevtools initialIsOpen={false} />
</QueryClientProvider>
);
}
export default MyApp;++/code>++/code>++/pre>
From now, we will use the ++code>/nocache++/code> API route to simulate a bad configured API. We have to handle the cache with react-query only, like in my project context...
Create a new client page (++code>/react-query++/code>) for instance
++pre>++code>++code>// /pages/react-query.tsx
import type { NextPage } from "next";
import { ROOT_URL } from "../src/constants";
import { Post } from "../src/types/api/post";
import { Card } from "../src/atoms/Card";
import { useQuery } from "react-query";
import Link from "next/link";
const fetchPosts = async () => {
const res = await fetch(`${ROOT_URL}/nocache`);
const response = await res.json();
return response;
};
const ReactQuery: NextPage = () => {
const { data, isLoading } = useQuery<Post[]>("posts", fetchPosts, {
staleTime: 10000,
});
return (
<div
style={{ display: "flex", flex: 1, flexDirection: "column", padding: 24 }}
>
<Link href="/">
<a>Home</a>
</Link>
{isLoading &&<p>Loading data...</p>}
{!!data && data.map((item) =><Card key={item.id} title={item.title} />)}
</div>
);
};
export default ReactQuery;++/code>++/code>++/pre>
If you navigate from home to ++code>/react-query++/code> page you should see that the first time your API call is done, but for the next 10 seconds (the react-query ++code>staleTime++/code> parameter is set to 10000ms), the data come from cache. Indeed, no API call to ++code>/nocache++/code> route is done the second time I navigate to the ++code>/react-query++/code> page.
{% video_player "embed_player" overrideable=False, type='scriptV4', hide_playlist=True, viral_sharing=False, embed_button=False, autoplay=False, hidden_controls=False, loop=False, muted=False, full_width=False, width='2880', height='1184', player_id='55227945258', style='' %}
As you can see, react-query has an efficient cache with a lot of parameters in addition to all its features (loading and error states, hooks, mutations, cache invalidation, etc...). So it is already a better solution than the built-in fetch cache. But here we have set up a client side cache, so if my application is used my 4000 users, then my Big Query will be called a minimum of 4000 times each day (supposing my data is cached for 24 hours).
Let's dive into server-side cache!
The previous step makes us write a page which called the API client side. Let's transform it in a new page with server side API call:
++pre>++code>++code>// /pages/react-query-ssr.tsx
import type { NextPage } from "next";
import { ROOT_URL } from "../src/constants";
import { Post } from "../src/types/api/post";
import { Card } from "../src/atoms/Card";
import { QueryClient, useQuery } from "react-query";
import Link from "next/link";
import { dehydrate } from "react-query/hydration";
const fetchPosts = async () => {
const res = await fetch(`${ROOT_URL}/nocache`);
const response = await res.json();
return response;
};
const queryClient = new QueryClient();
const STALE_TIME = 10000;
export const getServerSideProps = async () => {
await queryClient.prefetchQuery("posts", fetchPosts, { staleTime: STALE_TIME });
return {
props: {
dehydratedState: dehydrate(queryClient),
},
};
};
const ReactQuery: NextPage = () => {
const { data, isLoading } = useQuery<Post[]>("posts", fetchPosts, {
staleTime: STALE_TIME,
});
return (
<div
style={{ display: "flex", flex: 1, flexDirection: "column", padding: 24 }}
>
<Link href="/">
<a>Home</a>
</Link>
{isLoading &&<p>Loading data...</p>}
{!!data && data.map((item) =><Card key={item.id} title={item.title} />)}
</div>
);
};
export default ReactQuery;++/code>++/code>++/pre>
Once you have done this change, when you load the page, you should not see a loading state anymore. Indeed, your data are loaded server side: the server renders your HTML page and send it to your browser, so the loading step is skipped.
Important: maybe you have seen that I changed the way to declare the QueryClient server side compared to the React Query documentation. Indeed, here, I declare the client outside the ++code>getServerSideProps++/code> function. Thus, my client is kept from one client to another. If I had declared the client inside the function, then the cache would be deleted each new ++code>getServerSideProps++/code> call, so it is useless for my use case.
By reproducing the previous step to test the cache use, you can observe that:
This proof of concept was enough for validating my tech strategy for this project. I found how to:
If you want to dive deeper in the subject of cache for web application, I advise you to look at the Redis database used to store in-memory structured data. For instance, you can store your request results from Big Query in the Redis database, and read them from your client application. It is very fast, scalable and popular. Even Google provides a service to deploy a Redis database with its Memorystore. Finally, explore what is a CDN, it could help you ?
And you, what solution did you choose to improve your data-fetch?


Le BAM Innovation Lab, pour rester à la pointe des dernières innovations tech et produit !









